今天想把實務上的一段小插曲記下來:公司機房有 MSI 單卡 RTX-5090 的伺服器,但現場有兩個限制:沒有 sudo 權限(無法安裝系統服務、無法啟用 docker),因團隊無法 VPN 連線進行 LLM 訓練,因此授權我進行測試才拿到帳號。
雖然能透過 ssh 臨時替代 VPN,但接下來的問題很快出現:我原本想用 Hugging Face 提供的 **gpt-oss ** 來跑卻發現它import pipeline需要即時編譯(runtime compilation)、底層依賴安裝,這些都必須透過 sudo 才能處理 → 直接卡關。
最後的折衷方案是:「使用 Python + Transformers + bitsandbytes 的 4-bit 量化路徑,將 Qwen-3 以 4bit 載入並在 5090 上推理」,這樣剛好能在不改系統、不需要 sudo 的情況下完成,且顯存不會爆掉。
原則:不需要 sudo、使用使用者層級環境、用 4-bit 量化 + bitsandbytes 載入。
如果公司沒有 conda,但能用 venv:
python3 -m venv ~/venvs/qwen3
source ~/venvs/qwen3/bin/activate
python -m pip install --upgrade pip --user
或若能用 conda(無需 sudo):
conda create -n qwen3 python=3.10 -y
conda activate qwen3
pip install --user torch torchvision --index-url https://download.pytorch.org/whl/cu118
pip install --user transformers accelerate bitsandbytes safetensors
備註:選擇與機器 CUDA 版本相符的 PyTorch wheel。若網路限制,預先把 wheel 下載到可存取的位置再安裝。
# run_qwen3_4bit.py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "your-qwen3-30b-4bit-path-or-id"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
load_in_4bit=True, # 啟用 4-bit 載入
bnb_4bit_compute_dtype=torch.float16, # 計算 dtype(可改為 float16)
trust_remote_code=True
)
inputs = tokenizer("Hello, world", return_tensors="pt").to("cuda")
with torch.no_grad():
out = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(out[0], skip_special_tokens=True))
執行:
python run_qwen3_4bit.py
device_map="auto" 讓 accelerate / transformers 自動分配顯卡/CPU 記憶體。bnb_4bit_compute_dtype=torch.float16(或 torch.bfloat16 若硬體支援)能降低 GPU 計算記憶體。max_new_tokens、更短的 batch size 與 torch.no_grad() 控制記憶體峰值。device_map={'': 'cpu'} 結合逐層 offload),或使用 max_memory 在 accelerate 配置中設定上限。原本只是想在 5090 上跑個推理測試,結果一路踩坑:
最後我還坑自己一把想了個解法,就是包成一個 互動式聊天腳本,以及一個 API 伺服器,讓團隊能直接呼叫。
存成 chat_qwen3_30B_4bit.py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
import os
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# 建議啟用 PyTorch 記憶體配置優化
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# 4bit 量化設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
# 載入 tokenizer 和模型
print("🚀 載入模型中,可能需要一些時間...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=bnb_config,
offload_folder="offload" # ✅ 超出 VRAM 的部分會自動丟到這裡
)
# 初始化對話紀錄
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
print("💬 已載入完成,可以開始對話 (輸入 exit 離開)")
while True:
user_input = input("👤 You: ")
if user_input.strip().lower() in ["exit", "quit"]:
print("👋 再見!")
break
# 加入使用者訊息
messages.append({"role": "user", "content": user_input})
# 準備輸入
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成模型回覆
print("🤖 Assistant (思考中...)")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024, # ✅ 每次回覆上限 token 數
do_sample=True,
top_p=0.9,
temperature=0.7
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
assistant_reply = tokenizer.decode(output_ids, skip_special_tokens=True)
# 印出回覆
print(f"🤖 Assistant: {assistant_reply}\n")
# 將回覆加入對話紀錄
messages.append({"role": "assistant", "content": assistant_reply})
使用方式:
python chat_qwen3_30B_4bit.py
可以一直輸入問題,模型會記得之前的對話,直到輸入 exit 或 quit 結束。
不想用命令列互動,我包成 API 服務。
1️⃣ 安裝必要套件
pip install fastapi uvicorn
2️⃣ 新增 server.py
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch, os
# ===== 模型初始化 =====
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
print("🚀 載入模型中,可能需要一些時間...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=bnb_config,
offload_folder="offload"
)
# ===== FastAPI 應用 =====
app = FastAPI()
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
model: str
messages: list[Message]
max_tokens: int = 512
@app.post("/v1/chat/completions")
def chat(req: ChatRequest):
text = tokenizer.apply_chat_template(
[{"role": m.role, "content": m.content} for m in req.messages],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=req.max_tokens,
do_sample=True,
top_p=0.9,
temperature=0.7
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
reply = tokenizer.decode(output_ids, skip_special_tokens=True)
return {
"id": "chatcmpl-001",
"object": "chat.completion",
"choices": [
{"index": 0, "message": {"role": "assistant", "content": reply}}
]
}
if __name__ == "__main__":
import sys, uvicorn
port = int(sys.argv[1]) if len(sys.argv) > 1 else 8000
uvicorn.run("server:app", host="0.0.0.0", port=port)
3️⃣ 啟動服務
python server.py 50010
或用 uvicorn:
uvicorn server:app --host 0.0.0.0 --port 50010
這樣同事就能用 POST /v1/chat/completions 來呼叫,格式幾乎跟 OpenAI API 一樣。
4️⃣ 測試 API
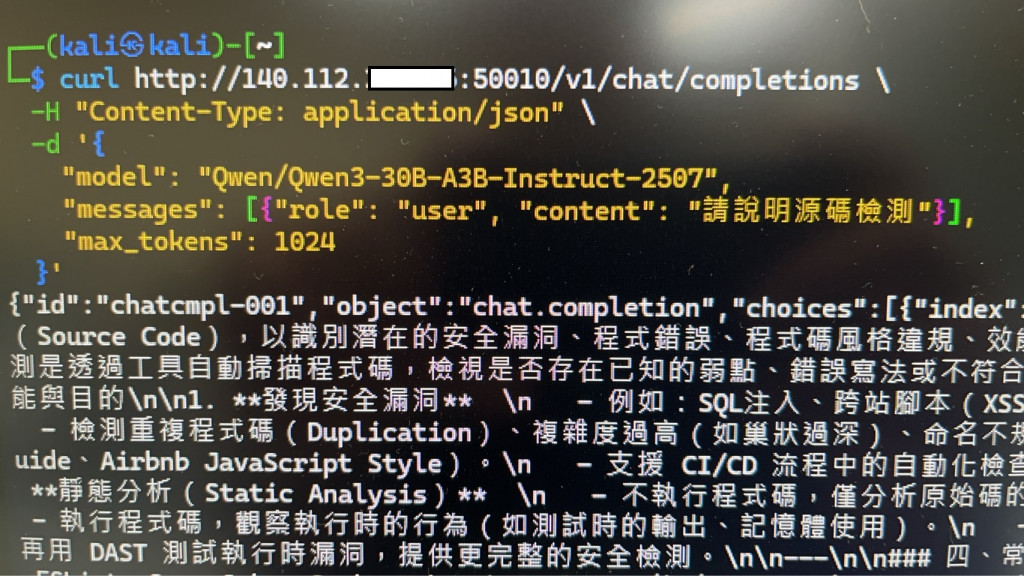
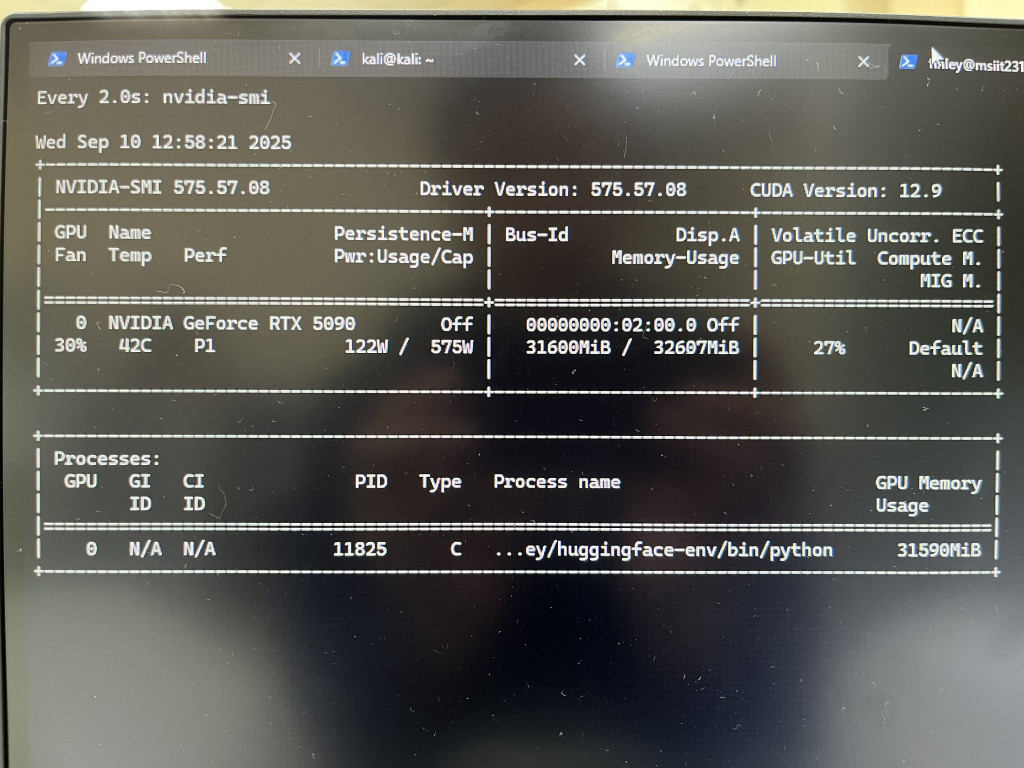
我自以為的多做了好多事情超前部屬,花了一整天的時間解決連線問題又做好測試環境,隔天早上打算來收割一下成果的時候主管在後面問我那個console的畫面在幹嘛!甚麼,這算力要保證全部都給團隊使用。
我把API關了,uvicorn取消開機執行,主管講完我便再也沒有登入過那台設備。結果團隊只要能連線就好,以上程式碼就當是我夢到的想要用的朋友就拿去吧。但沒有這一段也不會有這篇Day 2就是了🤣


 iThome鐵人賽
iThome鐵人賽